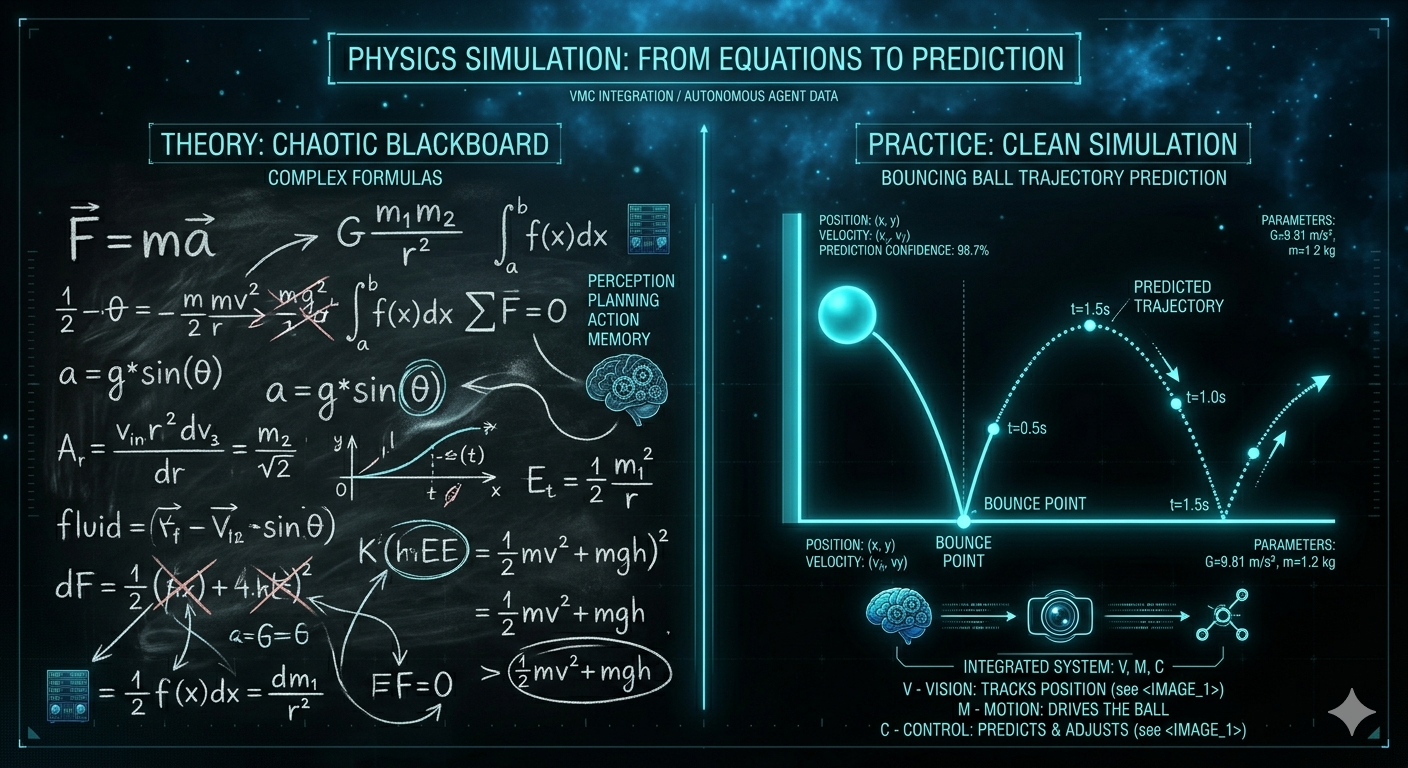
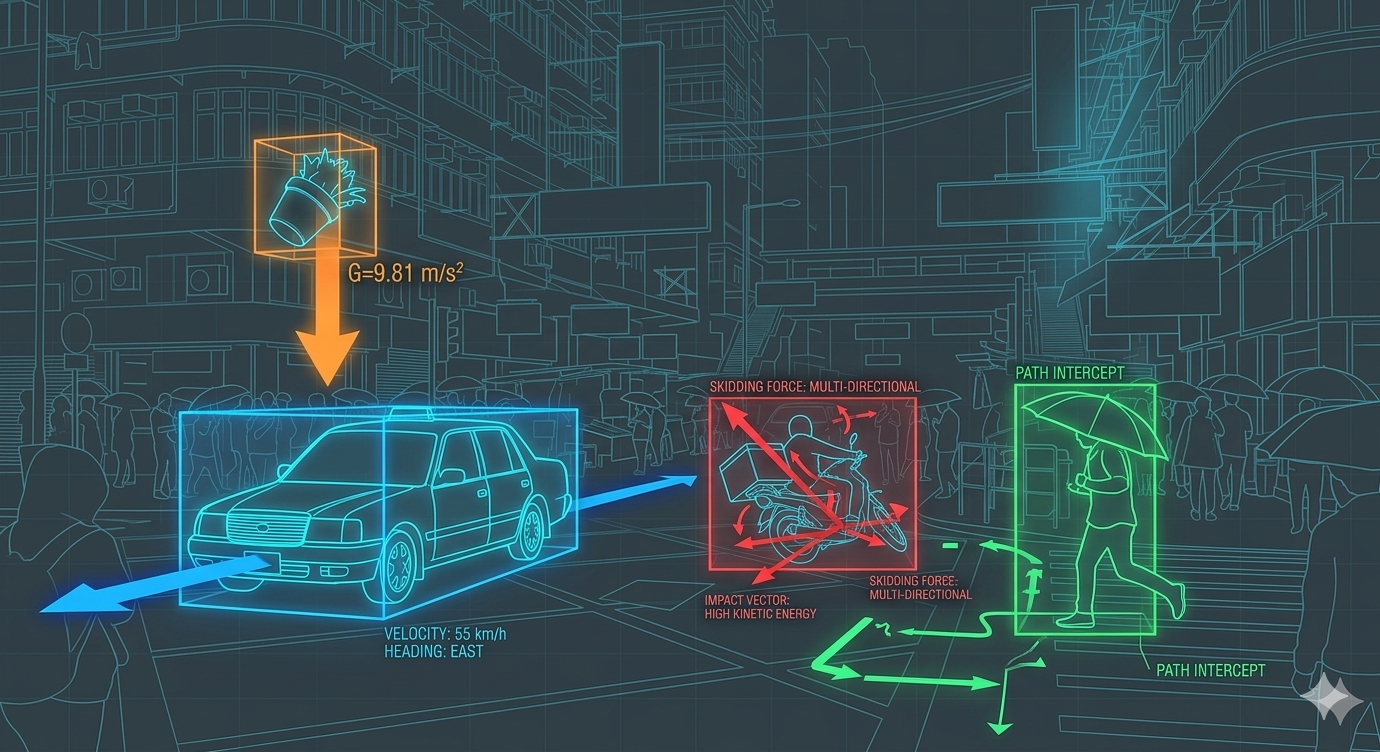
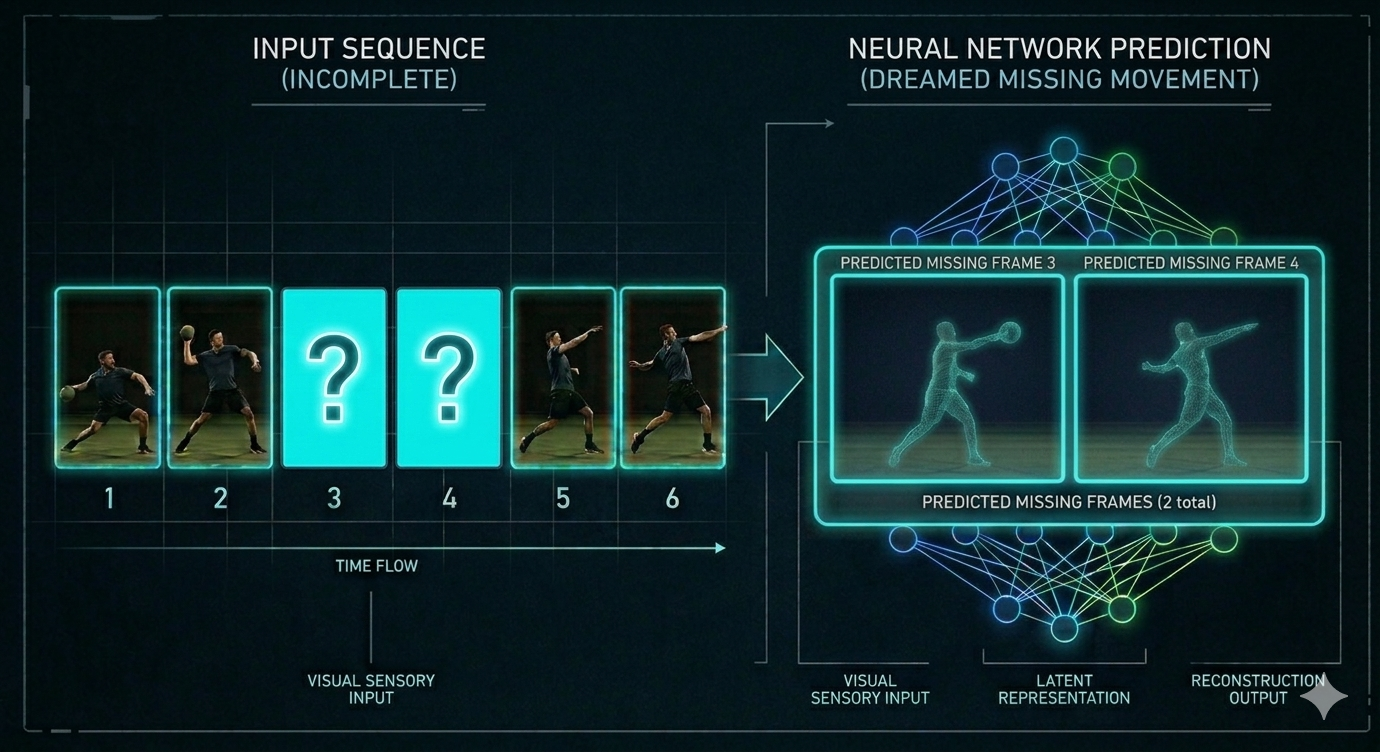
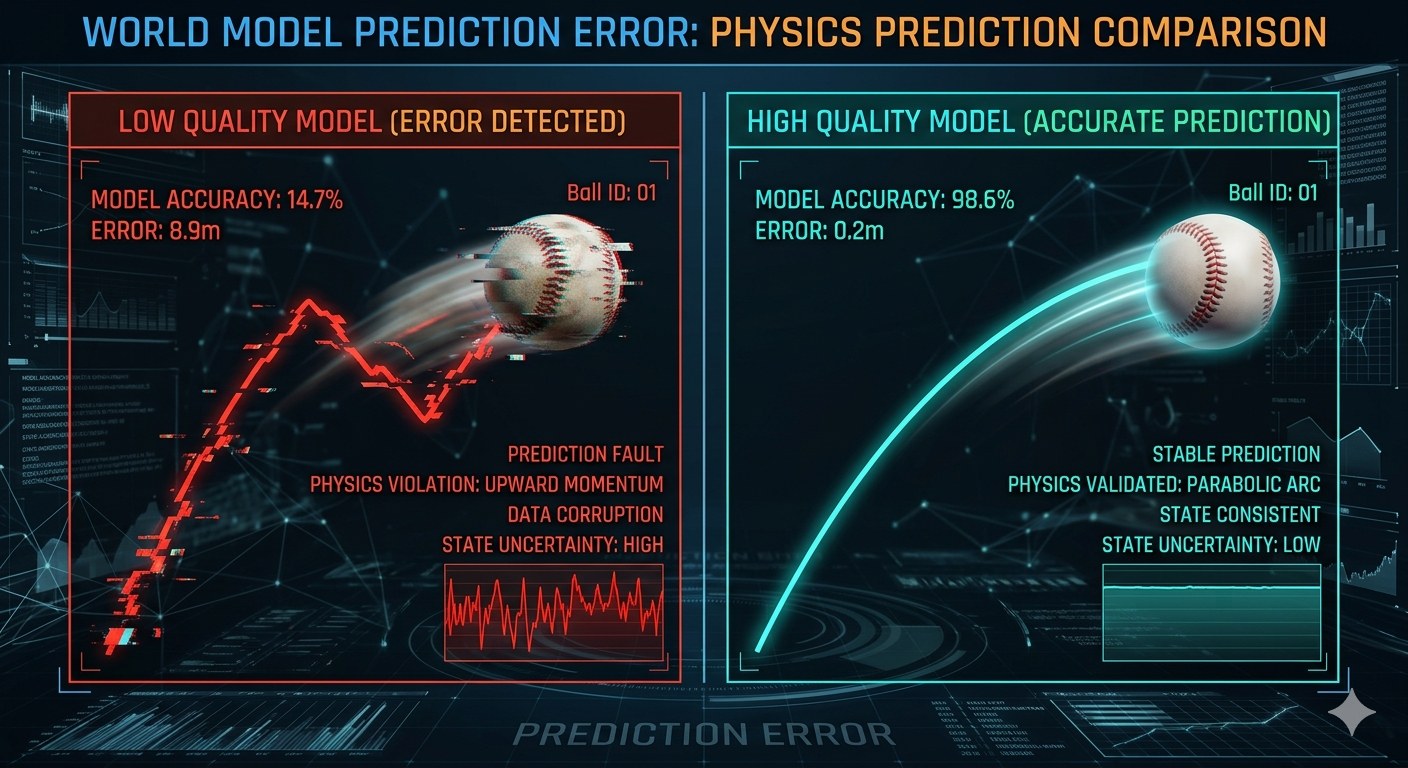
Bisherige KIs wie ChatGPT sind Meister der Sprache, aber "blind" für die Realität. Sie bewegen sich in einem Raum aus reinen Symbolen. Dieses Problem nennt man das Symbol Grounding Problem: Die KI kennt zwar das Wort "Apfel" und weiß, dass andere Wörter wie "Baum" oder "lecker" mit ihm in Verbindung stehen, aber ihr fehlt die Verbindung zum physikalischen Objekt, seiner Haptik oder wie er wirklich riecht und schmeckt.
Yann LeCun ist Chief AI Scientist bei Meta und einer der drei "Godfathers of AI", den Paten der modernen KI. Er ist überzeugt, dass LLMs niemals echte Intelligenz (AGI) erreichen können. Seine Lösung: Weltmodelle.