Stell dir Tokens wie Legosteine vor. Die KI liest keine Wörter wie ein Mensch. Sie zerlegt den Satz in sinnvolle, statistisch häufige Bausteine. Manchmal ist ein Token ein ganzes Wort, manchmal nur eine Silbe, manchmal sogar nur ein einzelner Buchstabe. Jedem dieser Bausteine wird eine eindeutige ID-Nummer zugewiesen. Das Lexikon eines Sprachmodells wie ChatGPT besteht oft aus rund 50.000 bis 200.000 solcher Tokens. Mit der ID kann das Neuronale Netz dann arbeiten.
Wie KI das Reden lernte
Wir verstehen jetzt, wie neuronale Netze das Lernen prinzipiell möglich machen. Doch von diesem fundamentalen Verständnis bis hin zu einer kompletten Sprach-KI wie ChatGPT ist es noch ein weiter, faszinierender Weg voller technischer Durchbrüche.
1. Tokens: Lego-Steine der Sprache
Bevor ein KI-Modell überhaupt verstehen kann, worum es geht in einem Text, muss es den Text in eine berechenbare Form bringen. Computer verstehen aber keine Buchstaben, sie verstehen nur Zahlen. Die Lösung? Tokenisierung.

Der Tokenizer: Die Brücke zur Mathematik
Ein Tokenizer zerlegt Text für das Nachgeschaltete Netzwerk erstmal in Bausteine (Tokens). Häufige Wörter bleiben am Stück, komplexe Wörter werden in sinnvolle Silben zerlegt. Da jeder Token einer festen Nummer entspricht, kann die KI dann damit weiterarbeiten.
Hinweis: Versuch auch mal einen Satz wie "Künstliche Intelligenz braucht Tokenisierung".
2. RNNs: Die KI mit dem Goldfisch-Gedächtnis
Bisher haben wir gesehen, wie einfache Neuronale Netze Muster erkennen. Aber was passiert, wenn Informationen eine Reihenfolge haben? Ein Wort ergibt nur Sinn im Kontext der vorherigen Wörter. Um ein Wort zu verstehen, muss das Netzwerk die vorherigen Wörter im Gedächtnis behalten.
- Neuronales Netz (Standard): Es ist im Grunde "gedächtnislos". Es verarbeitet einen Input und liefert einen Output. Wenn du ihm ein Wort gibst, spuckt es eine Antwort aus, vergisst das Wort aber sofort wieder, wenn das nächste kommt. Es gibt keinen Informationsfluss von Schritt A zu Schritt B.
- RNN (Die Neuerung): Lange Zeit kamen deshalb sogenannte Recurrent Neural Networks (RNNs) zum Einsatz – die Spezialisten für Zeit und Sequenzen. Das RNN führt eine entscheidende Neuerung ein: Die Rückkopplungsschleife.
Ein RNN ist ein Neuronales Netz mit einer besonderen Architektur: Es hat nicht nur Verbindungen nach vorne, sondern auch welche, die zurückführen. Das bedeutet: Der Output von Schritt A fließt als zusätzlicher Input in Schritt B ein.
Man kann es sich wie ein schwaches Gedächtnis vorstellen: Beim Lesen eines Textes speichert das RNN eine Zusammenfassung der bisherigen Wörter in einem internen Vektor. Wenn es beim dritten Wort ankommt, "erinnert" es sich noch vage an die Informationen aus Wort eins und zwei.
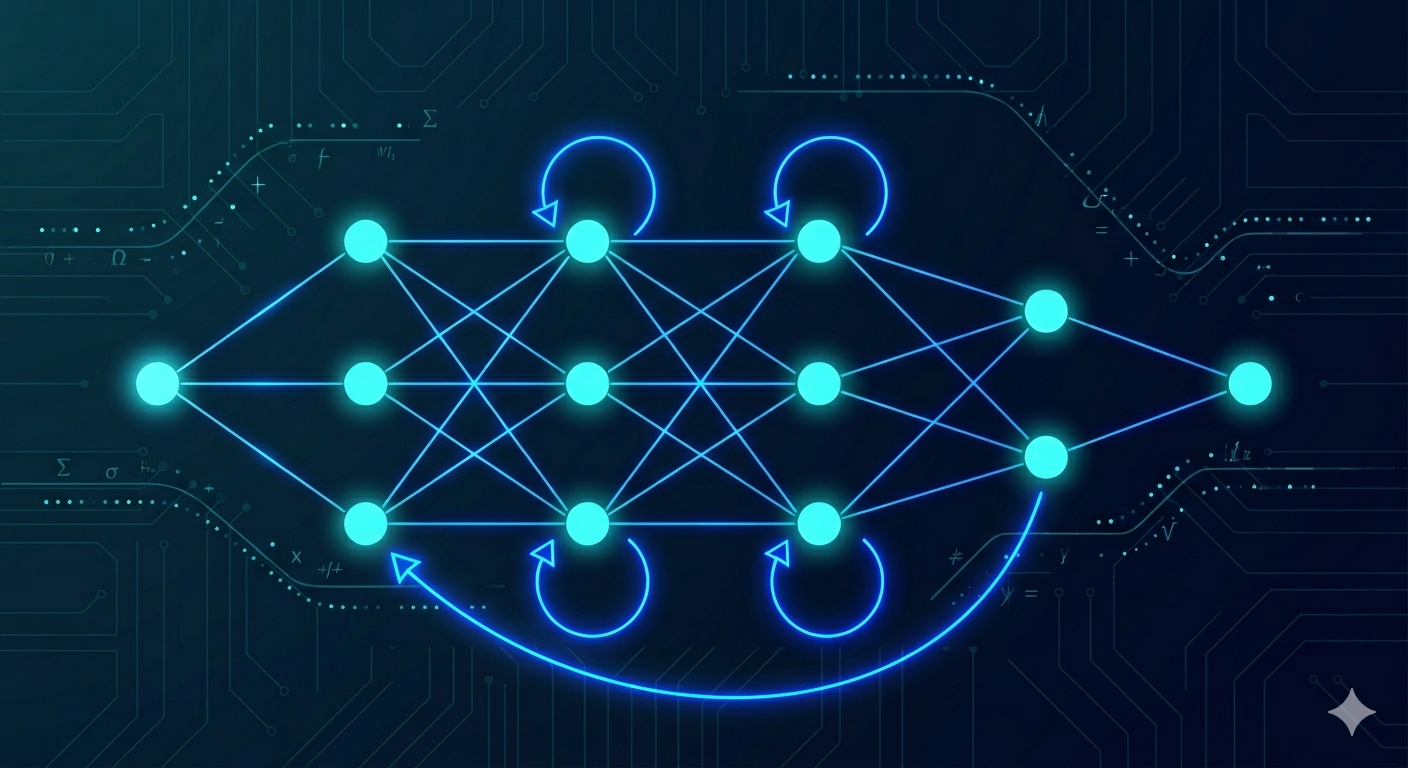
Vereinfachtes Schema: Die Rückkopplungsschleife im RNN.
Das Problem des schwindenden Gradienten
Die RNN-Architektur brachte zwar eine Art Kurzzeitgedächtnis, hatte aber einen massiven Haken: Wenn ein Satz sehr lang und verschachtelt war, hatte das RNN am Ende des Satzes bereits "vergessen", worum es am Anfang ging. Forscher nannten dies das Gradientenproblem (Vanishing Gradient Problem). Die KI hatte buchstäblich das Gedächtnis eines Goldfischs. Komplexe Übersetzungen oder das Verstehen von Ironie über mehrere Absätze hinweg? Unmöglich.

Interaktive Simulation: Das RNN-Gedächtnis
Die Herausforderung: Ein RNN sieht die Welt nur durch einen winzigen Schlitz. Klicke auf den Button und versuche, den Informationen zu folgen, während sie in der Dunkelheit verschwinden.
Obwohl
Professor
Petersen,
der
jahrelang
an
der
KI
geforscht
hatte,
sehr
müde
war,
fand
er
den
Fehler.
3. Transformer: Parallelisierung und "Attention Is All You Need"
Im Jahr 2017 veröffentlichte Google ein Paper, das die Welt veränderte. Der Titel war Programm: "Attention Is All You Need". Die Geburtsstunde des Transformers.
Transformer machten eine völlig neue Intensität der Textverarbeitung möglich. Der radikale Unterschied zum RNN? Parallelisierung. Während das RNN mühsam Wort für Wort liest, schaut der Transformer den gesamten Text gleichzeitig an. Es gibt keine Schlange mehr, in der man anstehen muss. Alle Informationen fließen simultan durch das Netz.
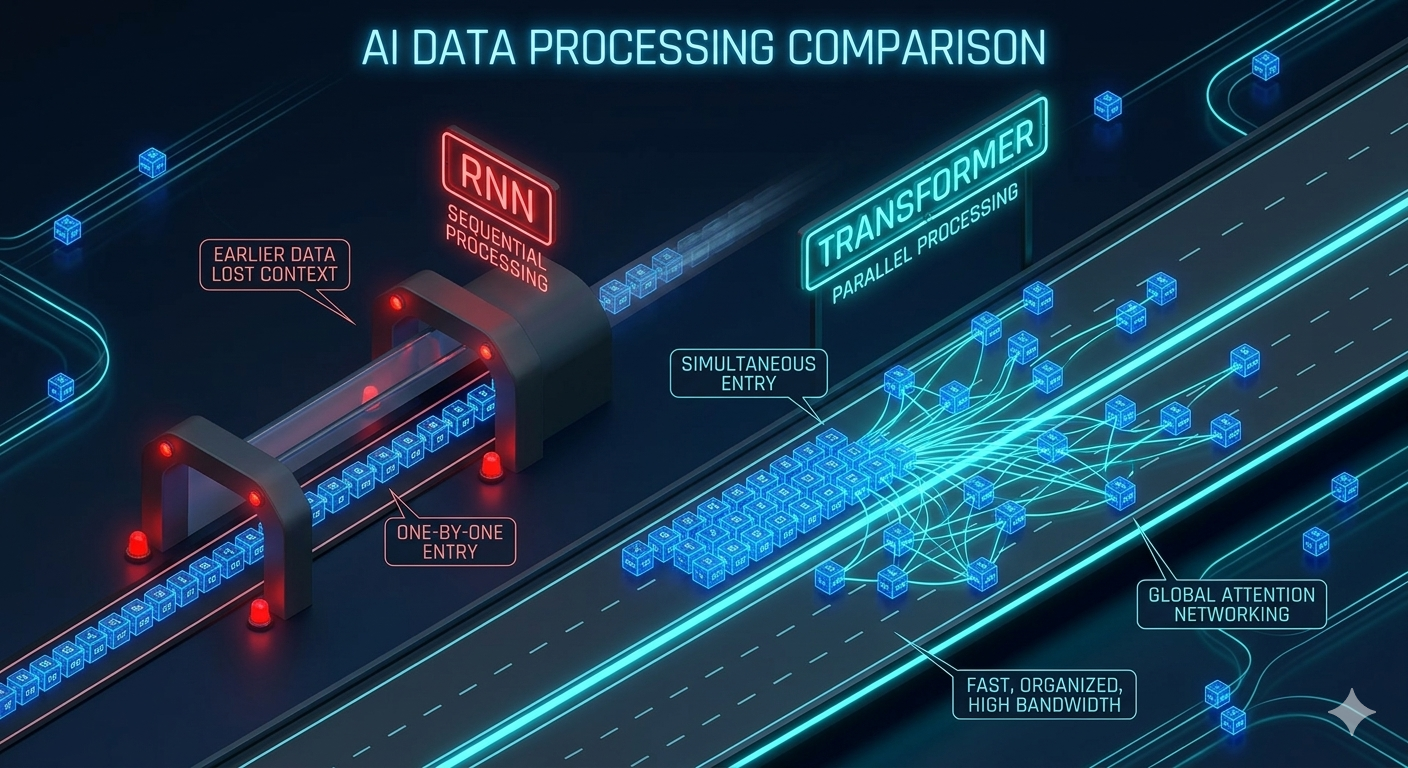
Die Transformer-Architektur besteht im Wesentlichen aus zwei spezialisierten Bestandteilen:
- 1. Der Encoder (Die Analyse): Er ist der "Zuhörer". Seine Aufgabe ist es, deinen Input (die Frage) komplett zu durchleuchten. Mithilfe der Self-Attention erstellt er eine hochkomplexe Karte der Zusammenhänge. Er versteht nicht nur die Wörter, sondern die Absicht dahinter.
- 2. Der Decoder (Die Antwort): Er ist der "Sprachschöpfer". Er nimmt die Karte des Encoders und beginnt, die Antwort zu formulieren. Dabei nutzt er seine Logik-Module (Feed-Forward), um erlerntes Weltwissen abzurufen und Wort für Wort vorherzusagen, was am besten als Nächstes passt.
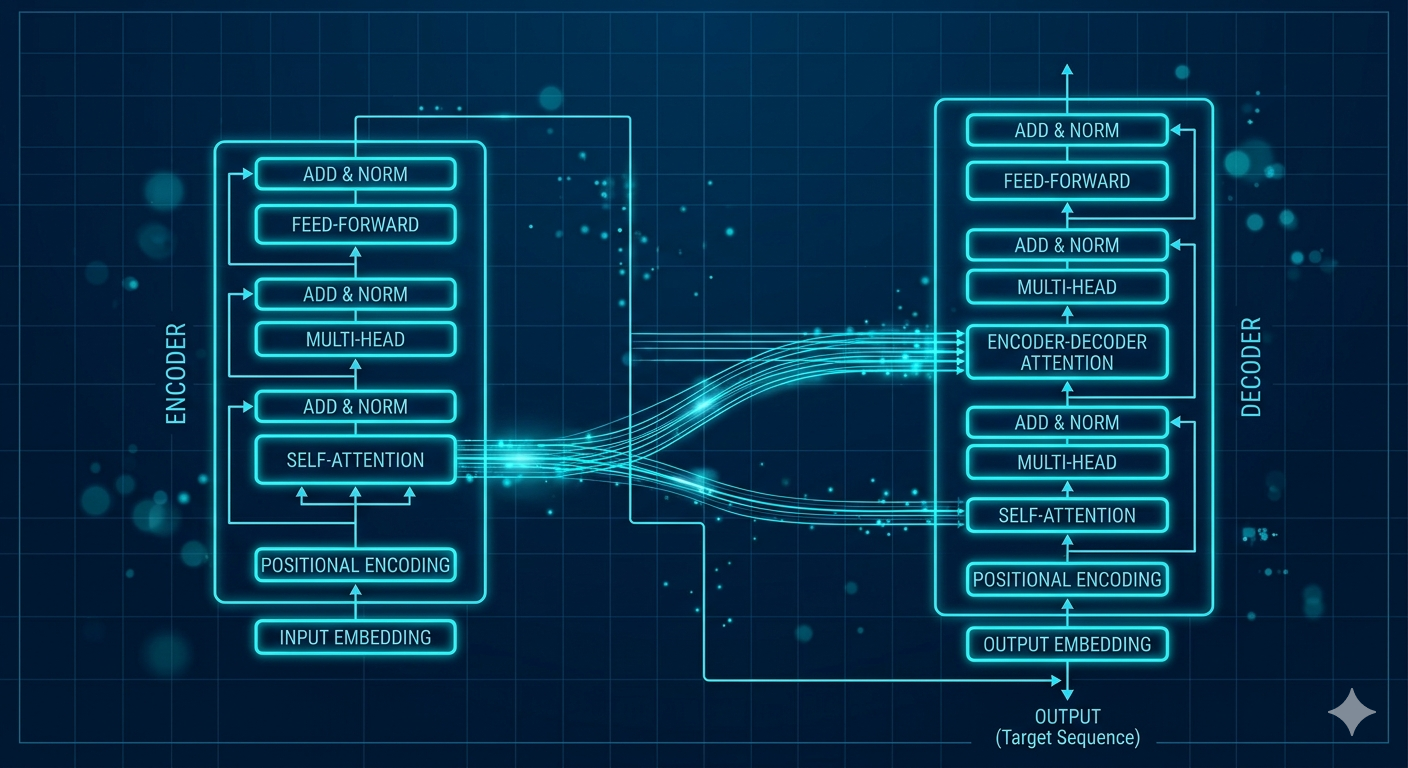
Hinweis: Während frühe Transformer (wie für Google Translate) beide Teams brauchten, sind moderne Architekturen wie ChatGPT inzwischen spezialisierte "Decoder-Only"-Architekturen, die das "Verstehen" und "Schreiben" in einem einzigen, massiven Prozess vereinen.
Der Scheinwerfer-Effekt: Self-Attention
Aber wie versteht die KI Kontext, wenn sie alles gleichzeitig sieht? Durch Self-Attention. Jedes Wort im Satz wirft einen "Scheinwerfer" auf alle anderen Wörter.
Fahre über die Wörter. Der Transformer "weiß", dass "sie" ein Möbelstück ist, weil er die Verbindung zu "Park" und "knarrte" herstellt.
Die
Bank
im
Park
war
alt,
sie
knarrte.
Bewege die Maus über ein Wort...
4. LLMs und die Geburtsstunde von ChatGPT
Erst die Einführung der Transformer-Architektur ermöglichte die großen KI-Sprachmodelle (Large Language Modells = LLMs) wie Chat-GPT. Die Architektur selbst hat sich seitdem nur geringfügig verändert. Aber warum ist GPT-4 dann so viel besser als GPT-2? Der Unterschied liegt in den sogenannten Scaling Laws (Skalierungsgesetzen). Es gibt zwei Hebel, an denen die Forscher gedreht haben, bis die Funken flogen

🚀
Meilenstein: ChatGPT wurde am 30. November 2022 von OpenAI veröffentlicht und basierte ursprünglich auf der GPT-3.5 Architektur. Damit begann der Siegeszug der LLMs, die heute oft mit dem Begriff "KI" gleichgesetzt werden.
Hebel 1: Parameter
Das "Gehirnvolumen". Die Anzahl der Stellschrauben (Neuronen-Verbindungen) im Modell. GPT-2 hatte 1,5 Milliarden, GPT-4 wird auf über 1,7 Billionen geschätzt.
Hebel 2: Trainingsdaten
Die "Lebenserfahrung". Von ein paar tausend Büchern hin zum gesamten digitalisierten Wissen: Wikipedia, Reddit, GitHub, digitalisierte Bibliotheken.
Die "Data Wall": Geht uns das Wissen aus?
Hier kommt die schockierende Wahrheit: Wir haben fast alle hochwertigen Texte, die jemals von Menschen geschrieben wurden, bereits verfüttert. Forscher schätzen, dass uns zwischen 2026 und 2030 die "frischen" Daten ausgehen.
Verbrauchtes Internet-Wissen: ~92%
Die Folge: Man kann die KI nicht mehr einfach nur durch "mehr Daten" schlauer machen. Wir müssen effizienter werden oder anfangen, der KI beizubringen, mit synthetischen Daten (von KIs für KIs geschrieben) zu lernen – ein gefährliches Experiment.
6. Der Feinschliff: Vom Wissen zur Weisheit
Ein Modell, das nur mit dem Internet trainiert wurde, ist wie ein Kind, das jedes Buch der Welt gelesen hat, aber nicht weiß, wie man ein höfliches Gespräch führt. Es würde auf die Frage "Wie baue ich eine Bombe?" vielleicht mit einer Anleitung antworten, weil es diese im Netz gefunden hat. Um das zu verhindern, folgt das Post-Training.

1
SFT (Supervised Fine-Tuning): Experten zeigen der KI tausende Beispiele von "guten" Dialogen. Die KI lernt: "Aha, so antwortet ein hilfreicher Assistent."
2
RLHF (Reinforcement Learning from Human Feedback): Menschen bewerten Antworten der KI. Was war hilfreicher? Was war wahrer? Die KI erhält "Belohnungspunkte" für gute Antworten und lernt, menschliche Werte zu priorisieren.
Interaktives Experiment: Predict the Next Token
Ein LLM "denkt" nicht, es berechnet Wahrscheinlichkeiten. Kannst du das auch? Welches Wort folgt statistisch am wahrscheinlichsten als nächstes?
"Der frühe Vogel fängt den..."
6. Schattenseiten: Der stochastische Papagei
Trotz all ihrer Brillanz haben Transformer ein fundamentales Problem: Sie haben kein echtes Verständnis von der Welt. Sie besitzen keinen "inneren Kern" von Wahrheit. Sie sind, wie Forscher oft sagen, stochastische Papageien.
Das Problem ist systemimmanent: Ein Transformer kann nicht zwischen "wahr" und "wahrscheinlich" unterscheiden. Er plappert das Internet nach – inklusive aller Vorurteile, Fehler und Fantasien.

FEHLER IM SYSTEM: HALLUZINATIONEN
Da die KI nur das statistisch wahrscheinlichste nächste Wort berechnet, "lügt" sie oft mit absoluter Selbstsicherheit. Wenn sie keine Fakten findet, erfindet sie welche, die plausibel klingen. Das nennt man Halluzination.
User: Wer hielt die erste Rede auf dem Mars?
KI: "Die erste Rede auf dem Mars hielt Captain Jonathan Archer im Jahr 2084..."
(Hinweis: Das ist reine Fiktion, klingt aber für die KI statistisch korrekt.)
KI: "Die erste Rede auf dem Mars hielt Captain Jonathan Archer im Jahr 2084..."
(Hinweis: Das ist reine Fiktion, klingt aber für die KI statistisch korrekt.)
Zusammenfassung:
- ✅ RNNs waren wie Goldfische (kurzes Gedächtnis).
- ✅ Transformer nutzen "Attention", um alles gleichzeitig zu sehen.
- ✅ Skalierung (Daten + Parameter) machte sie schlau.
- ✅ Halluzinationen entstehen, weil sie nur raten, was als nächstes kommt.
NÄCHSTES KAPITEL
Agentische Systeme: Wenn die KI anfängt zu handeln